JPA
고급 매핑
No-ah98
2022. 4. 5. 00:54
목차
- 상속 관계 매핑
- @MappedSuperclass
- 실전 예제 - 4. 상속관계 매핑
상속관계 매핑
- 객체는 상속관계 존재 O, 관계형 데이터베이스는 상속 관계 존재X
- 그나마 슈퍼타입 서브타임 관계라는 모델링 기법이 객체 상속과 유사
- 상속관계 매핑 : 객체의 상속과 구조와 DB의 슈퍼타입 서브타입 관계를 매핑

슈퍼타입 서브타입 논리 모델을 실제 물리 모델로 구현하는 방법
- 객체는 상속을 지원하므로 모델링과 구현이 같지만, DB는 상속을 지원하지 않기 때문에 논리 모델을 물리 모델로 구현할 방법이 필요하다.
- 구현 방법
- 주요 어노테이션
- @Inheritance(stategy=InheritanceType.xxxx)의 stategy를 부모 클래스에서 설정해주면 됨
- InheritanceType 종류
- JOINED
- SINGLE_TABLE (default)
- TABLE_PER_CLASS
- InheritanceType 종류
- @DiscriminatorColumn(name ="DTYPE")
- 부모 클래스에 선언한다. 하위 클래스를 구분하기 위해 사용한다.
- @DiscriminatorValue("XXX")
- 하위클래스에 선언한다. 엔티티 저장 시, 슈퍼타입 구분 컬럼에 저장할 값을 지정한다.
- 어노테이션을 선언하지 않으면 클래스 이름이 기본값이다.
- @Inheritance(stategy=InheritanceType.xxxx)의 stategy를 부모 클래스에서 설정해주면 됨
- 참고※) JPA에서는 아래 방법 3가지 중 어느 방식을 선택하든 매핑이 가능하도록 지원한다.
- 각각 테이블로 변환 -> 조인 전략
- 통합 테이블로 변환 -> 단일 테이블 전략
- 서브타입 테이블로 변환 -> 구현 클래스마다 테이블 전략
- 주요 어노테이션
객체의 상속관계 구현
Item(부모 클래스)
@Entity
@Inheritance(strategy = InheritanceType.XXX) // 상속 구현 전략 선택
public class Item {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private int price;
}Album(자식 클래스)
@Entity
public class Album extends Item {
private String artist;
}
Moive(자식 클래스)
@Entity
public class Movie extends Item {
private String director;
private String actor;
}Book(자식 클래스)
@Entity
public class Book extends Item {
private String author;
private String isbn;
}조인 전략
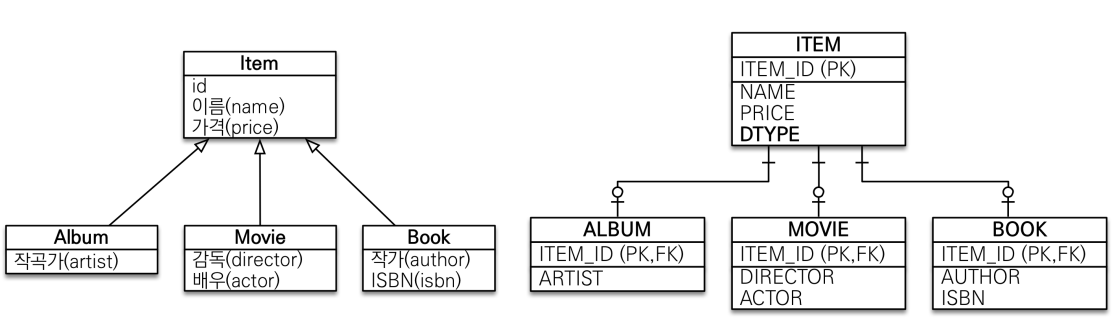
- 상속관계 매핑에서 "정석"이라고 생각하면 된다. 보통 비즈니스적으로 중요하고 복잡할 때 사용한다.
- NAME, PRICE가 공통 속성으로 ITEM 테이블에만 저장되고, 자식 테이블은 각자 데이터만을 저장한다.
- 장점
- 테이블 정규화
- 외래 키 참조 무결성 제약조건 활용가능
- 저장공간 효율화
- 단점
- 조회시 조인을 많이 사용, 성능 저하
- 조회 쿼리가 복잡함
- 데이터 저장 시 INSERT SQL 2번 호출
- Item 엔티티 - @Ingeritance(strategy = InheritanceType.JOINED) 전략
- 하이버네이트의 조인 전략에서는 @DiscriminatorColumn을 선언하지 않으면 DTYPE 칼럼이 생성되지 않는다.
- 하지만 조인하면 앨범인지 무비인지 알 수 있다. 그래도 DTYPE을 넣어서 명확하게 해주는게 낫다.
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
@DiscriminatorColumn // 하위 테이블의 구분 컬럼 생성(default = DTYPE)
public class Item {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private int price;
}실제 실행된 DDL
- 테이블 4개 생성 (ITEM, ALBUM, BOOK, MOVIE)
- 하위 테이블에 FK 생성, 하위 테이블은 ITEM_ID가 PK이면서 FK로 잡아야 한다.
- 조인 전략에 맞는 테이블들이 생성됨.
Hibernate:
create table Album (
artist varchar(255),
id bigint not null,
primary key (id)
)
Hibernate:
create table Book (
author varchar(255),
isbn varchar(255),
id bigint not null,
primary key (id)
)
Hibernate:
create table Item (
DTYPE varchar(31) not null,
id bigint generated by default as identity,
name varchar(255),
price integer not null,
primary key (id)
)
Hibernate:
create table Movie (
actor varchar(255),
director varchar(255),
id bigint not null,
primary key (id)
)
Hibernate:
alter table Album
add constraint FKcve1ph6vw9ihye8rbk26h5jm9
foreign key (id)
references Item
Hibernate:
alter table Book
add constraint FKbwwc3a7ch631uyv1b5o9tvysi
foreign key (id)
references Item
Hibernate:
alter table Movie
add constraint FK5sq6d5agrc34ithpdfs0umo9g
foreign key (id)
references ItemMovie 객체 생성했을 때
- Insert 쿼리가 2개 나간다.
- Item 테이블, Movie 테이블 저장.
- DTYPE에 클래스 이름이 디폴트로 저장
- 참고) 조회할 때는 innert join을 통해서 조회한다.
Movie movie = new Movie();
movie.setDirector("DirectorA");
movie.setActor("ActorB");
movie.setName("title");
movie.setPrice(10000);
em.persist(movie); //영속성
tx.commit(); // 트랙잭션 커밋Hibernate:
/* insert advancedmapping.Movie
*/ insert
into
Item
(id, name, price, DTYPE)
values
(null, ?, ?, 'Movie')
Hibernate:
/* insert advancedmapping.Movie
*/ insert
into
Movie
(actor, director, id)
values
(?, ?, ?)단일 테이블 전략(SINGLE_TABLE)

- 논리 모델을 한 테이블로 합쳐버림
- "DTYPE"으로 구분
- -> @DiscriminatorColumn 필수 (디폴트로 설정 되어있음)
- 서비스 규모가 크지 않고, 굳이 조인 전략을 선택해서 복잡하게 갈 필요 없이 테이블을 단순하게 할 때 사용
- 장점
- 한 테이블에 다 저장하기 때문에 조인이 필요 없으므로 일반적으로 조회 성능이 빠르다
- 조회 쿼리가 단순하다.
- 단점
- 자식 엔티티가 매핑한 컬럼은 모두 null 허용
- 데이터 무결성 위반
- 한 테이블에 모두 저장하므로 테이블이 커질 수 있다. 상황에 따라 조회 성능이 느려질 수 있다.
- 자식 엔티티가 매핑한 컬럼은 모두 null 허용
@Entity
@DiscriminatorColumn
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
public class Item {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private int price;
}실행된 DDL
- 통합 테이블이 하나 생성된다.
Hibernate:
create table Item (
DTYPE varchar(31) not null,
id bigint generated by default as identity,
name varchar(255),
price integer not null,
artist varchar(255),
author varchar(255),
isbn varchar(255),
actor varchar(255),
director varchar(255),
primary key (id)
)조인 전략에서 실습했던 Movie 저장, 조회 예제를 그대로 돌려보면
- 한 테이블에 있으므로 Item 테이블을 조회한다. 이때, DTYPE을 검색 조건으로 추가해서 조회한다.
Hibernate:
select
movie0_.id as id2_0_0_,
movie0_.name as name3_0_0_,
movie0_.price as price4_0_0_,
movie0_.actor as actor8_0_0_,
movie0_.director as director9_0_0_
from
Item movie0_
where
movie0_.id=?
and movie0_.DTYPE='Movie'구현 클래스마다 테이블 전략(TABLE_PER_CLASS)

- 이 전략은 데이터베이스 설계자와 ORM 전문가 둘 다 추천 X
- 슈퍼 타입의 컬럼들을 서브 타입으로 내린다. 즉, NAME, PRICE 컬럼이 중복되도록 허용하는 전략이다.
- 구현 클래스마다 테이블을 생성한다. (슈퍼타입 클래스 생성 X)
- 슈퍼타입 클래스는 실제 생성되는 테이블이 아니므로 abstract 클래스여야 하고, 테이블을 구분해줄 DTYPE이 필요 없기 때문에 @DiscriminatorColumn도 필요가 없어진다.
- 참고) @Inheritance의 TABLE_PER_CLASS와 @Id의 생성 전략 GenerationType.IDENTITY를 같이 사용하면 에러 발생
- @Id의 GenerationType을 TABLE 타입으로 변경 적용해서 해결. 그리고 시퀀스 테이블 생성을 방지하기 위해 이것에 대한 매핑까지 추가해주자
- 문제점
- 객체지향 프로그래밍에서는 MOVIE, ALBUM, BOOK 객체를 ITEM 타입으로도 조회할 수 있기 때문에 조회 시 union all로 전체 하위 테이블을 다 찾는다. 굉장히 비효율적으로 동작.
상속관계 매핑 정리
- 조인 전략
- 장점
- 테이블 정규화 되어있음
- 외래 키 참조 무결성 제약조건 활용가능
- 저장공간 효율화
- 단점
- 조회시 조인을 많이 사용, 성능 저하 (실제로는 크게 차이 없음)
- 조회 쿼리가 복잡함
- 데이터 저장시 INSERT SQL 2번 호출
- 정리
- 단점으로 성능 저하가 있지만 실제로 크게 차이가 없다.
- 저장공간이 효율화 된다.
- 기본적으로 조인 정략이 정석이다. 설계가 깔끔하게 나온다
- 하지만 테이블이 단순 + 데이터 양이 적음 + 확장 가능성 X -> 단일 테이블 전략이 더 좋은 선택이다.
- 장점
- 단일 테이블 전략
- 장점
- 테이블이 하나기 때문에 조인이 필요 없으므로 조회 성능이 빠르다
- 조회 쿼리가 단순하다.
- 단점
- 자식 엔티티가 매핑한 컬럼은 모두 NULL 허용 -> 데이터 무결성 위반
- 단일 테이블에 모든 것을 저장하므로 테이블이 커질 수 있다.
- 상황에 따라서 조회 성능이 오히려 느질 수 있다.
- 이 상황에 해당하는 임계점을 넘을 일이 많지 않다.
- 장점
- 구현 클래스마다 테이블 전략
- 데이터 베이스 설계자와 ORM 전문가 둘다 추천 X -> 쓰지 말자.
- 장점
- 서브 타입을 명확하게 구분해서 처리할 때 효과적이다.
- NOT NULL 제약조건 사용할 수 있다.
- 단점
- 여러 자식 테이블을 조회할 때 성능이 느리다(UNION SQL 필요)
- 자식 테이블을 통합해서 쿼리하기 어려움
@MappedSuperclass
- 객체 입장에서 공통 매핑 정보가 필요할 때 사용 ( ex. id, name은 객체 입장에서 계속 나옴)
- 공통 속성을 상속받아서 사용하고싶을 때 사용
- 상속관계 매핑으로 착각할 수 있는데 아니다.
- 엔티티 X, 테이블과 매핑 X
- 부모 클래스를 상속 받는 자식 클래스에 매핑 정보만 제공
- 조회, 검색 불가(em.find(BaseEntity)불가)
- 직접 생성해서 사용할 일이 없으므로 추상 클래스 권장
- 겍체 입장에서 나온 어노테이션 이기 때문에 DB 테이블과는 상관없다.
- 단순히 엔티티가 공통으로 사용하는 매핑 정보를 모으는 역할
- 주로 등록일, 수정일, 등록자, 수정자 같은 전체 엔티티에서 공통으로 적용하는 정보를 모을 때 사용
- 참고: @Entity 클래스는 엔티티(상속 관계 매핑)나 @MappedSuperclass로 지정한 클래스만 상속 가능
- 참고2 : 실무에서는 누가 수정했는지 파악하기 위해 기본적으로 사용한다.

코드로 이해하기
- 상황 : 생성자, 생성시간, 수정자, 수정시간을 모든 엔티티에 공통으로 포함
- 아래와 같이 BaseEntity를 정의해서 활용
- 매핑정보만 상속받는 Superclass라는 의미의 @MappedSuperclass 어노테이션 선언
BaseEntity
@Getter
@Setter
@MappedSuperclass
public abstract class BaseEntity {
private String createdBy;
private LocalDateTime createdDate;
private String lastModifiedBy;
private LocalDateTime lastModifiedDate;
}Member (BaseEntity 상속)
@Entity
public class Member extends BaseEntity {
...
}실행된 DDL ( BaseEntity에 선언된 컬럼들이 생성 )
Hibernate:
create table Member (
id bigint generated by default as identity,
createdBy varchar(255),
createdDate timestamp,
lastModifiedBy varchar(255),
lastModifiedDate timestamp,
age integer,
description clob,
roleType varchar(255),
name varchar(255),
locker_id bigint,
team_id bigint,
primary key (id)
)
Hibernate:
create table Team (
id bigint generated by default as identity,
createdBy varchar(255),
createdDate timestamp,
lastModifiedBy varchar(255),
lastModifiedDate timestamp,
name varchar(255),
primary key (id)
)
...